
Machine Learning: The Ultimate Guide for Beginners

This comprehensive guide explores the fundamentals of machine learning, breaking down complex concepts into actionable insights. You will learn about core algorithms, practical applications across industries, and expert strategies to implement models effectively. Whether you are a beginner or looking to refine your knowledge, this article provides the foundation you need.
Have you ever wondered how your favorite apps predict what you want before you even ask? Machine learning is the powerful technology driving these intelligent systems and transforming modern digital experiences.
Understanding the Basics of Intelligent Systems
Machine learning represents a monumental shift in how we approach problem-solving in computer science. Instead of explicitly programming a computer to perform a task, we provide it with data and allow it to identify patterns, make decisions, and improve over time. This capability is reshaping industries from healthcare to finance, enabling unprecedented levels of automation and predictive accuracy.
To grasp the true potential of machine learning, you must first understand how it differs from traditional programming. In traditional programming, humans write the rules (code) and provide data to get answers. In machine learning, humans provide data and answers, and the system discovers the rules. This paradigm shift allows us to tackle problems that are too complex for manual rule-creation, such as image recognition, natural language processing, and advanced anomaly detection.
The importance of high-quality data cannot be overstated. Machine learning models are only as good as the data they are trained on. If you feed a model biased, incomplete, or noisy data, the resulting predictions will be flawed. Data scientists spend a significant portion of their time collecting, cleaning, and preprocessing data to ensure their models have the best possible foundation for learning.
How Machine Learning Works
The machine learning process typically follows a structured pipeline. Understanding this pipeline is crucial for anyone looking to build or deploy these models effectively.
First, we start with data collection. This involves gathering raw data from various sources, such as databases, APIs, or sensors. Once the data is collected, it moves into the preprocessing phase. This is where missing values are handled, outliers are addressed, and categorical variables are encoded into numerical formats that algorithms can process.
Next comes feature engineering, which is the process of selecting, modifying, or creating new features from the raw data to improve model performance. This step requires deep domain knowledge and creativity. After the features are prepared, the data is split into a training set and a testing set.
The training phase is where the actual machine learning happens. The algorithm processes the training data, adjusting its internal parameters to minimize errors and identify underlying patterns. Once the model is trained, it is evaluated using the testing set. This helps us understand how well the model generalizes to new, unseen data. If the performance is satisfactory, the model is deployed into a production environment where it can make predictions on live data.
Categories of Machine Learning Algorithms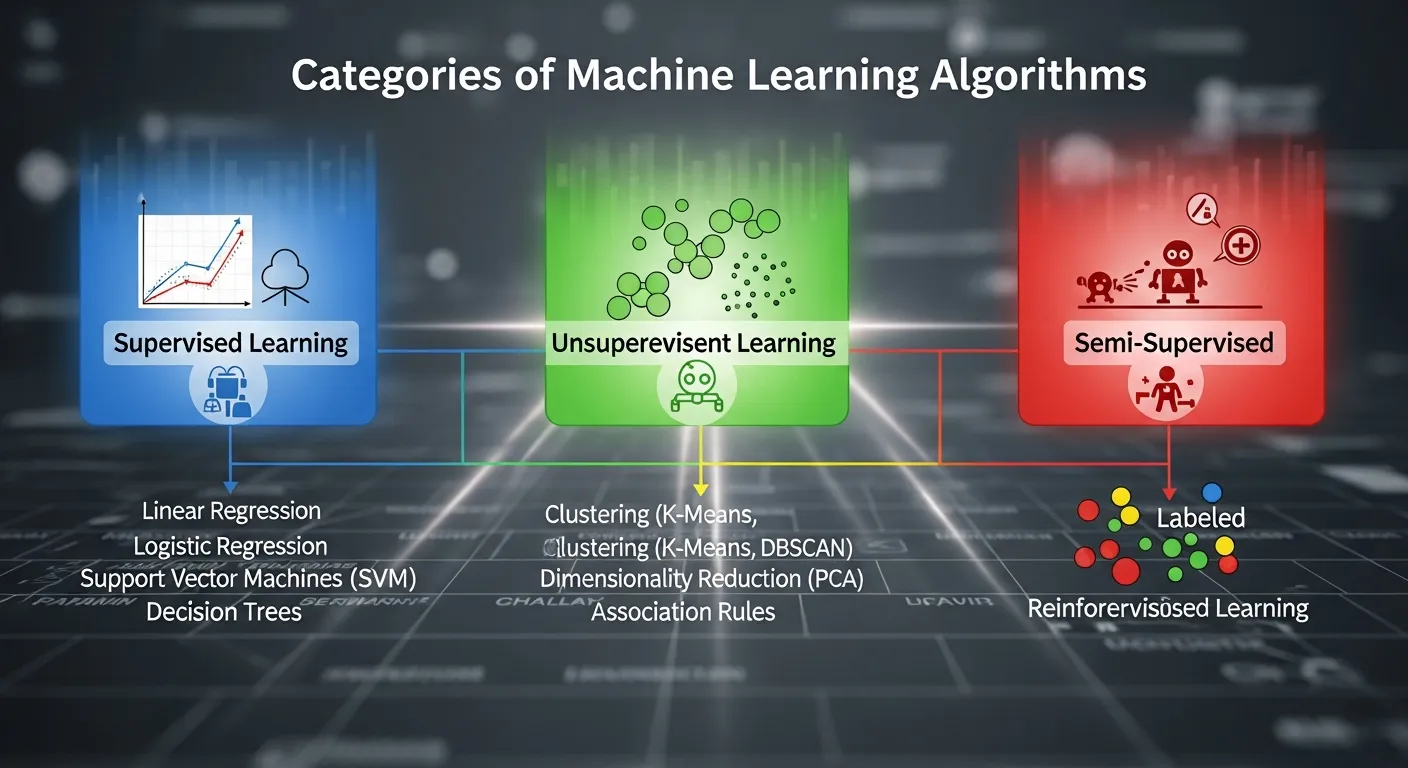
Machine learning encompasses several distinct approaches, each suited to different types of problems and data.
Supervised Learning
Supervised learning is the most common approach. In this method, the model is trained on a labeled dataset, meaning the input data is paired with the correct output. The goal is for the model to learn the mapping from inputs to outputs so it can predict the output for new, unlabeled inputs. Common applications include spam detection, price prediction, and medical diagnosis. Popular algorithms in this category include linear regression, decision trees, and support vector machines.
Unsupervised Learning
Unsupervised learning involves training a model on data that has no labels. The system must discover the hidden structures and patterns within the data on its own. This approach is widely used for clustering customers into segments, identifying anomalies in network traffic, and reducing the dimensionality of complex datasets. K-means clustering and principal component analysis are classic examples of unsupervised algorithms.
Reinforcement Learning
Reinforcement learning takes a completely different approach. Here, an agent learns to interact with an environment to achieve a specific goal. The agent performs actions and receives feedback in the form of rewards or penalties. Through trial and error, the agent learns to maximize its cumulative reward. This is the technology behind self-driving cars, advanced robotics, and systems that can master complex games like chess or Go.
Real-World Applications
The impact of machine learning is visible across nearly every sector of the modern economy.
In healthcare, models are analyzing medical images to detect diseases like cancer earlier and with greater accuracy than human experts. They are also being used to predict patient readmission rates and discover new pharmaceutical drugs by simulating molecular interactions.
The finance industry relies heavily on machine learning for algorithmic trading, fraud detection, and credit scoring. By analyzing millions of transactions in real-time, models can flag suspicious activity and block fraudulent charges before they affect consumers.
Retailers use these systems for demand forecasting, inventory management, and personalized product recommendations. When an e-commerce platform suggests an item you might like, it is using a complex recommendation engine powered by machine learning.
Structured Comparison: Supervised vs. Unsupervised Learning

|
Feature |
Supervised Learning |
Unsupervised Learning |
|---|---|---|
|
Data Type |
Labeled data |
Unlabeled data |
|
Primary Goal |
Predict outcomes for new data |
Discover hidden patterns |
|
Complexity |
Generally simpler to evaluate |
More complex to evaluate |
|
Common Algorithms |
Linear Regression, Random Forest |
K-Means, DBSCAN, PCA |
|
Use Cases |
Spam filtering, Image classification |
Customer segmentation, Anomaly detection |
Common Mistakes to Avoid
When implementing machine learning projects, teams often fall into several predictable traps. Avoiding these pitfalls can save significant time and resources.
- Ignoring Data Quality: Building complex models on messy data will yield poor results. Always prioritize data cleaning and preprocessing.
- Overfitting the Model: Overfitting occurs when a model learns the training data too well, including its noise, making it perform poorly on new data. Use techniques like cross-validation and regularization to prevent this.
- Skipping Feature Engineering: Relying solely on raw data limits model performance. Invest time in creating meaningful features that highlight important relationships in the data.
- Neglecting the Baseline: Always establish a simple baseline model before moving to complex deep learning architectures. Often, a basic linear model performs surprisingly well.
- Failing to Monitor in Production: Models can degrade over time as real-world data distributions change (data drift). Continuous monitoring and retraining are essential.
Pro Tips for Success
To elevate your machine learning projects, consider these expert insights:
- Start Simple: Begin with the most basic algorithm that could possibly solve your problem. Only increase complexity when necessary.
- Focus on Business Value: Ensure your model solves a real business problem rather than just acting as a technical experiment.
- Embrace Version Control: Use tools to version your data, code, and models. This ensures reproducibility and easier collaboration.
- Understand the Math: While modern libraries abstract much of the complexity, having a solid grasp of linear algebra, calculus, and statistics will help you troubleshoot models effectively.
- Read Widely: The field evolves rapidly. Keep up with authoritative sources. For instance, you can find excellent research on the OpenAI website, stay updated with industry applications on the Google AI Blog, and master practical implementation through Machine Learning Mastery.
Building a Strong Foundation
If you want to master machine learning, you need a robust foundation in programming and mathematics. Python is widely considered the best language for this field due to its readable syntax and massive ecosystem of libraries like Scikit-learn, TensorFlow, and PyTorch.
Begin by mastering data manipulation using Pandas and NumPy. Once you are comfortable handling data, move on to building simple models. Practice is crucial. Participate in online competitions, build personal projects, and contribute to open-source repositories.
As you progress, dive deeper into specific subfields like Deep Learning, Natural Language Processing, or Computer Vision. Each of these areas requires specialized knowledge but offers incredible opportunities for innovation. Remember to leverage Data Visualization techniques to understand your datasets better and communicate your findings effectively to stakeholders.
The Future of the Field
Machine learning is not standing still. We are witnessing rapid advancements in areas like generative AI, where models can create entirely new text, images, and code. This opens up entirely new creative and operational possibilities for businesses.
Furthermore, there is a growing focus on explainable AI (XAI). As models become more complex, it becomes harder to understand how they make decisions. In industries like healthcare and finance, transparency is critical. XAI aims to make the decision-making processes of these “black box” models interpretable by humans.
Edge computing is another exciting frontier. Instead of sending data to centralized cloud servers for processing, machine learning models are being deployed directly on devices like smartphones and IoT sensors. This reduces latency, saves bandwidth, and improves privacy.
Machine learning is revolutionizing how we interact with technology and solve complex global challenges. By understanding its foundational algorithms, avoiding common pitfalls, and continuously refining your skills with high-quality data, you can build impactful, intelligent systems. Ready to dive deeper into data science? Start building your first model today and unlock the power of predictive analytics for your next big project.
FAQs
What is the simple definition of machine learning?
Machine learning is a branch of artificial intelligence where computer systems are given the ability to learn and improve from data without being explicitly programmed with rules for every scenario.
What is the difference between AI and machine learning?
Artificial Intelligence is the broader concept of machines being able to carry out tasks in a way that we would consider “smart.” Machine learning is a specific application of AI based on the idea that machines should be given access to data to learn for themselves.
Do I need a PhD to do machine learning?
No, you do not need a PhD. While advanced research roles might require one, many practitioners enter the field through bootcamps, online courses, and practical experience, focusing on applied problem-solving rather than theoretical research.
Which programming language is best for machine learning?
Python is the undisputed leader due to its simplicity and the vast ecosystem of dedicated libraries like TensorFlow, PyTorch, and Scikit-learn. R and Julia are also popular in academic and highly statistical environments.
What is overfitting in machine learning?
Overfitting happens when a model learns the details and noise in the training data to an extent that it negatively impacts the performance of the model on new data. It essentially memorizes the training set rather than learning the underlying patterns.
How much data is required to train a model?
The amount of data needed depends entirely on the complexity of the problem and the algorithm used. Simple linear models might work well with hundreds of examples, while deep learning models often require millions of data points to achieve high accuracy.
What is a neural network?
A neural network is a series of algorithms that endeavors to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates. They form the foundation of deep learning.
How does machine learning handle missing data?
Missing data can be handled in several ways: by removing the rows with missing values, by imputing (filling in) the missing values using statistical methods like the mean or median, or by using algorithms that can naturally handle missing inputs.
What is the role of a data scientist in machine learning?
A data scientist gathers and cleans data, selects the appropriate algorithms, trains the models, evaluates their performance, and communicates the insights to stakeholders to drive business decisions.
Is machine learning secure?
Like any technology, it has vulnerabilities. Models can be subject to adversarial attacks where intentionally designed input data tricks the model into making incorrect predictions. Ensuring model security and robustness is an active area of research.




